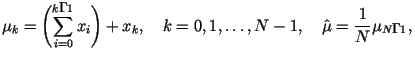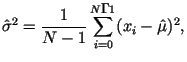Среднее значение и дисперсию вычислить несложно.
Однако при проведении вычислений на ЭВМ иногда возникают неожиданные
проблемы. Кроме того, на практике обычно неизвестна плотность
вероятности ![]() и, следовательно, расчет по формулам
(1.5) и (1.6) невозможен. Поэтому приходится оценивать
среднее значение и дисперсию по данным конечной протяженности с
использованием выражений (1.7) и (1.8).
и, следовательно, расчет по формулам
(1.5) и (1.6) невозможен. Поэтому приходится оценивать
среднее значение и дисперсию по данным конечной протяженности с
использованием выражений (1.7) и (1.8).
Среднее значение можно оценить простым усреднением всех значений временного ряда:
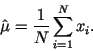
Существует другой метод оценивания среднего, который дает более точные
результаты. Он состоит в вычислении частных сумм следующим образом.
Пусть число данных равно степени двойки, т.е. ![]() , тогда вычисления
производят в
, тогда вычисления
производят в ![]() стадий:
стадий:
![\begin{eqnarray*}
\bar{x}_1(i)&=& \frac {1}{2} [x(2i)+x(2i+1)],~~~ i=0, \dots, \...
...\bar{x}_m(0)= \frac {1}{2} [\bar {x}_{m-1}(0)+\bar{x}_{m-1}(1)],
\end{eqnarray*}](img118.gif)
Для вычисления выборочного среднего значения часто также
применяют формулу:
Оценку дисперсии чаще всего производят по формуле
Существует также множество других способов расчета оценок средних значений и дисперсии. Об оценках никогда нельзя определенно сказать, что они верны или неверны, поскольку на практике точное значение оцениваемого параметра неизвестно. Тем не менее, некоторые оценки можно считать хорошими или лучшими по сравнению с другими. С практической точки зрения лучшим вариантом является расчет оценок различными способами и затем проведение анализа полученных результатов.